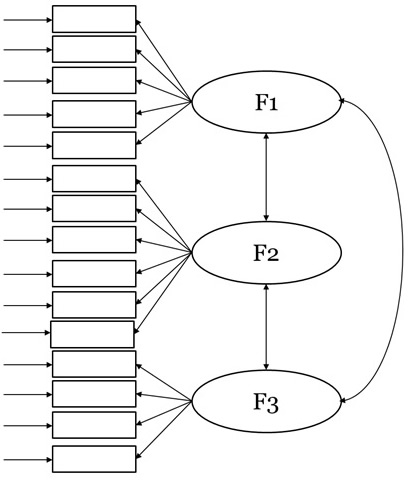
Figura 1. Modelo de tres factores oblicuos
http://dx.doi.org/10.24016/2017.v3n2.51
ARTÍCULOS ORIGINALES
Índices estadísticos de modelos bifactor
Statistical indices from bifactor models
Sergio Alexis Dominguez-Lara 1 * y Anthony Rodriguez 2
1 Universidad de San Martín de Porres, Perú.
2 University of California, United States of America.
Dirección de correspondencia: Instituto de Investigación de Psicología, Universidad de San Martín de Porres, Av. Tomás Marsano 242 (5to piso), Lima 34 – Perú; Teléfono: 0051988053909. Correo: sdominguezmpcs@gmail.com, sdominguezl@usmp.pe
Recibido: 24 de febrero de 2017
Revisado: 25 de junio de 2017
Aceptado: 26 de junio de 2017
Publicado Online: 29 de junio de 2017
CITARLO COMO:
Dominguez-Lara, S. & Rodriguez, A. (2017). Índices estadísticos de modelos bifactor. Interacciones, 3(2), 59-65 . doi: 10.24016/2017.v3n2.51
RESUMEN
Muchos instrumentos se crean con el propósito principal de evaluar sujetos con relación a un solo rasgo. Sin embargo, los rasgos psicológicos son frecuentemente complejos y contienen manifestaciones de dominio específico. Como tal, muchos instrumentos brindan información que son consistentes tanto con las estructuras unidimensionales como las multidimensionales. Por desgracia, muchas veces, los investigadores aplicados hacen determinaciones sobre la estructura final basado únicamente en los índices de ajuste obtenidos a partir de modelos de ecuaciones estructurales. Dado que los índices de ajuste generalmente favorecen al modelo bifactor sobre los modelos de medición competidores, es imperativo que los investigadores hacen uso de la información disponible que los modelos bifactor tienen para ofrecer con el fin de calcular los índices informativos incluyendo coeficientes de confiabilidad omega, confiabilidad del constructo, varianza común explicada, y el porcentaje de correlaciones no contaminadas. Dichos índices proporcionan información acerca de la fuerza tanto de los factores generales como de los factores específicos con el fin de sacar conclusiones acerca de la dimensionalidad y la puntuación global de las escalas (y subescalas). En este documento, se describen estos índices y ofrecen un nuevo módulo que facilita su cálculo.
PALABRAS CLAVE
Análisis factorial confirmatorio, bifactor, omega, confiabilidad del constructo, varianza común explicada, porcentaje de correlaciones no contaminadas.ABSTRACT
Many instruments are created with the primary purpose of scaling individuals on a single trait. However psychological traits are often complex and contain domain specific manifestations. As such, many instruments produce data that are consistent with both unidimensional and multidimensional structures. Unfortunately, oftentimes, applied researchers make determinations about the final structure based solely on fit indices obtained from structural equation models. Given that fit indices generally favor the bifactor model over competing measurement models it is imperative that researchers make use of the available information the bifactor has to offer in order to compute informative indices including omega reliability coefficients, construct reliability, explained common variance, and percentage of uncontaminated correlations. Said indices provide unique information about the strength of both the general and specific factors in order to draw conclusions about dimensionality and overall scoring of scales (and subscales). Herein, we describe these indices and offer a new module which easily facilitates their computation.
KEY WORDS
Confirmatory factorial analysis, bifactor, omega, construct reliability, explained common variance, percentage of uncontaminated correlations.
La construcción de instrumentos de evaluación psicológica bajo un enfoque analítico factorial normalmente busca la medición tanto de constructos amplios como de las dimensiones que los conforman, a fin de obtener información relevante para fines diagnósticos o de intervención. Ante ello, el supuesto de dimensionalidad teórica (p.e., que las dimensiones F1, F2 y F3 integran el constructo G) se traslada al plano empírico, y las puntuaciones de las tres dimensiones son adicionadas, configurando una puntuación total (puntuación F1 + puntuación F2 + puntuación F3 = puntuaciónG). En otras palabras, se asume que todos los ítems son influidos por la misma variable latente (p.e., Dominguez-Lara, 2014). Sin embargo, ello no es respaldado por información empírica que acredite la presencia de un factor de orden superior predominante, y la decisión se toma en base únicamente a las correlaciones entre las dimensiones (Figura 1), lo que podría tener un claro sentido teórico, pero necesita ser refrendado con datos empíricos.
Figura 1. Modelo de tres factores oblicuos
Es necesario resaltar que cuando las correlaciones entre las dimensiones son elevadas, puede hipotetizarse que esa relación se debe a la presencia de un factor general (FG; Reise, 2012). Este FG explicaría una mayor proporción de variabilidad de los ítems en comparación a los factores específicos (FEs), es decir, las dimensiones que lo integran. Por el contrario, si la correlación entre FEs es débil, probablemente el FG no explique una mayor variabilidad de los ítems que la explicada por los FEs de forma individual.
La influencia de este FG se analiza en el marco de los modelos jerárquicos, siendo el modelamiento bifactor o jerárquico directo (Canivez, 2016; Holzinger & Harman, 1938, Holzinger & Swineford, 1937; Reise, 2012; Reise, Morizot, & Hays, 2007) el más adecuado para evaluar simultáneamente la influencia del FG y FEs sobre la variabilidad de cada ítem. De este modo, podría valorarse si es pertinente la consideración de un FG de forma exclusiva, o de diferentes FEs, al evaluar determinado instrumento.
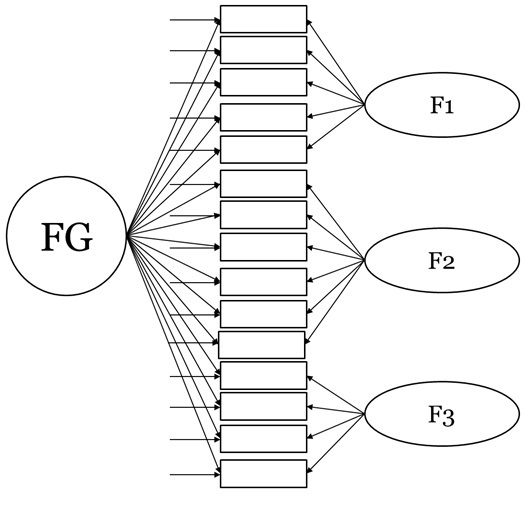
Figura 2. Modelo bifactor
Desde los modelos de ecuaciones estructurales (SEM), los modelos bifactor (Figura 2) se caracterizan por especificar en el modelamiento adicionalmente un FG que influye en todos los ítems de forma simultánea a los FEs (F1, F2, y F3, en la Figura 2). Los FE son modelados ortogonalmente ya que se parte de la hipótesis de que la varianza compartida entre ellos se debe a la presencia de un FG (Reise, 2012). El supuesto general del modelo es que el FG explica una mayor cantidad de varianza de los ítems en comparación a la que explican los FEs. Sin embargo, en ocasiones su evaluación bajo SEM puede llevar a falsos positivos si son considerados únicamente los índices de ajuste.
Por ejemplo, al evaluar un modelo bifactor y obtener índices de ajuste favorables (p.e., CFI > .95, RMSEA < .05), puede concluirse que es razonable suponer que el FG es la mejor explicación. En este caso, lo que se evalúa es el ajuste del modelo, pero no el grado de influencia del FG, en comparación a los FEs, sobre los ítems. Además, existe evidencia de que los índices de ajuste tradicionales (p.e. CFI, RMSEA, etc.) suelen favorecer a los modelos bifactor (Gignac, 2016; Morgan, Hodge, Wells, & Watkins, 2015).
Ese panorama se observa en estudios sobre engagement académico (Stefansson, Gestsdottir, Geldhof, Skulason, & Lerner, 2016), burnout académico (Morgan, de Bruin, & de Bruin, 2014; Tsubakita, & Shimazaki, 2016), etc.; donde los índices de ajuste del bifactor son favorables, incluso por encima de los otros modelos competidores, pero las magnitudes de las cargas factoriales de los FEs no difieren significativamente de las cargas factoriales del FG en el factor correspondiente (p.e., Stefansson et al., 2016), por lo que la consideración de un FG, y por ende una puntuación total, es cuestionable.
En este sentido, es necesario contar con índices estadísticos que permitan valorar la robustez del FG, así como evaluar si la contribución de los FEs que está por encima del FG es relevante, ya que frecuentemente el FG es lo suficientemente bueno, y no sería necesaria la evaluación de FE.
Existen diversos índices para valorar la fortaleza del FG. Por ejemplo, es utilizado el omega jerárquico (ωH; Zinbarg, Yovel, Revelle, & McDonald, 2006) para informar el monto de varianza total que puede ser atribuida al FG. Su cálculo se realiza con la siguiente fórmula:
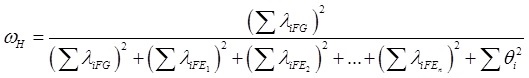
Por su parte, cada FE posee su omega jerárquico (ωhs) que refleja la varianza confiable de las puntuaciones por encima del FG (Rodriguez, Reise, & Haviland, 2016a). Su cálculo obedece a la siguiente expresión:
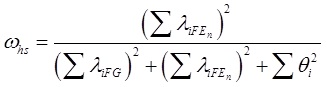
Para las dos fórmulas anteriores, λiFG se refiere a la carga factorial de cada ítem en el FG, λiFE a las cargas factoriales en cada FE, y θ2 es la varianza del error de cada ítem.
Como puede apreciarse, para el caso del ωH, mientras mayores sean las cargas factoriales en el FG, en contraste con las cargas en los FE, su magnitud será mayor. Del mismo modo, para ωhs, si las cargas factoriales de los ítems que pertenecen al FE son mayores en el FG, la magnitud de ωhs irá disminuyendo.
En cuando al ωH se esperan magnitudes ≥ .70 para concluir, al menos parcialmente, a favor de la unidimensionalidad (Reise , Scheines, Widaman, & Haviland., 2013); y para el caso del ωhs valores ≥ .30 podrían considerarse como significativas (Smits, Timmerman, Barelds, & Meijer, 2015).
Por su parte, el coeficiente Hh (Hancock, 2001; Hancock & Mueller, 2001) que es un método estadístico para evaluar cuán bien una variable latente es representada por un conjunto de ítems (Dominguez-Lara, 2016a). El coeficiente H no está limitado por la cantidad de grupos, y puede ser calculado también para el FG. En este caso, evalúa la confiabilidad de cada FE controlando el efecto del FG (> .70; Raykov, & Hancock, 2005). El cálculo del coeficiente Hh, sea para el FG o para cada FE, se realiza con la siguiente expresión:
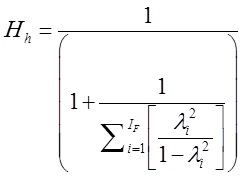
Donde IF representa al número de ítems en cada factor, tanto del FG como de los FEs; y el λ2 es la carga factorial al cuadrado (varianza) de cada ítem.
También es usual reportar el ECV (Explained Common Variance; Sijtsma, 2009; Ten Berge & Socan, 2004) que se interpreta como el monto de varianza común que se debe al FG. Un ECV mayor que .60 es indicador de que hay poca varianza común entre FE más allá que la del FG (Reise et al., 2013), y a nivel de ítem, el ECV-I (Stucky, Thissen, & Edelen, 2013) indica qué porcentaje de la varianza verdadera de cada ítem es explicada por el FG, esperando valores ≥ .80 para concluir sobre una influencia significativa del FG (Stucky, & Edelen, 2015). Como puede apreciarse, se excluye del análisis a la varianza del error, por lo que su análisis debe considerarse de forma conjunta con el ωH. Las expresiones matemáticas son:
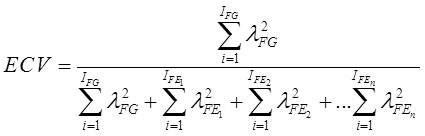
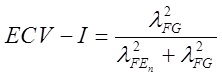
Por su parte, el PUC (Percentage of Uncontaminated Correlations; Reise et al., 2013) brinda información sobre el porcentaje de correlaciones no contaminadas por la multidimensionalidad (Rodriguez, Reise, & Haviland, 2016a), calculado con:
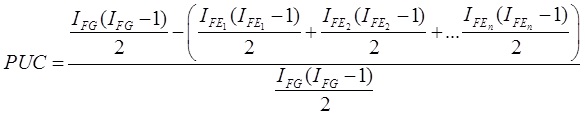
En las tres expresiones anteriores, IFG reflejan la cantidad ítems en el FG, IFE, la cantidad de ítems en cada FE, y λ2, la carga factorial al cuadrado (sea en FG o FE, según corresponda).
El PUC ayuda a interpretar prudentemente el ECV. Por ejemplo, si el ECV es > .70 y el PUC >. 70, se podría concluir a favor de la unidimensional (Rodriguez et al., 2016a); inclusive si el PUC es alto (> .80), incluso con magnitudes de ECV > .60 y ωH ≥ .70 informan favorablemente sobre la unidimensionalidad (Reise et al., 2013).
Esto es importante debido a que generalmente solo se observa el reporte del ωH, pero incluso si cuenta con una magnitud moderada o elevada, por sí mismo no es evidencia suficiente para concluir sobre la fortaleza del FG, ya que debe existir adicionalmente un ECV elevado.
Adicionalmente, es recomendable reportar la carga factorial promedio (λpromedio) tanto de los FEs como del FG con el objetivo de dar un índice general sobre la influencia de cada factor sobre los ítems.
No obstante, a pesar de su uso y utilidad en el ámbito de validación de instrumentos (ver Rodriguez, Reise, & Haviland, 2016b), no se hallan integrados en paquetes estadísticos (sea comerciales o de libre acceso), para que el usuario pueda obtenerlos fácilmente de forma conjunta. Existen programas informáticos ejecutables para procedimientos específicos (P.e., ωH y ωhs; Watkins, 2013), o extensiones compatibles con el entorno R (Rodriguez et al., 2016a), pero eso implica una configuración particular de la PC, o conocimiento de lenguaje de programación, lo que podría desalentar al investigador aplicado.
Propuesta de módulo
Bajo ese argumento fue construido un módulo en MS Excel (Indicebifactor.xls), que considera el cálculo de todos los índices mencionados anteriormente. La ventaja es que solo requiere ingresar las cargas factoriales estandarizadas de cada uno de los FEs y del FG.
Por ejemplo, en la columna S1 deben colocarse las cargas factoriales estandarizadas del primer FE, y al lado las cargas factoriales de esos ítems en el FG, y repetir el mismo procedimiento para todos los FE existentes (hasta un máximo de cinco FE). Una vez realizado aquello, los cálculos son automáticos. El módulo está disponible al lector sin costo en la sección de material complementario de la revista o escribiendo un correo electrónico al primer autor.
Para ejemplificar la funcionalidad del módulo, fueron usados los datos de la tabla 2 de Rodriguez et al. (2016a), donde evalúan una escala de ansiedad para niños, siendo la Ansiedad el FG, y los FEs las dimensiones Síntomas Físicos, Evitación del Daño, Ansiedad Social, y Ansiedad de Separación/Pánico. Todos los índices obtenidos son similares a los obtenidos en el citado estudio, por lo que los cálculos fueron programados eficientemente.
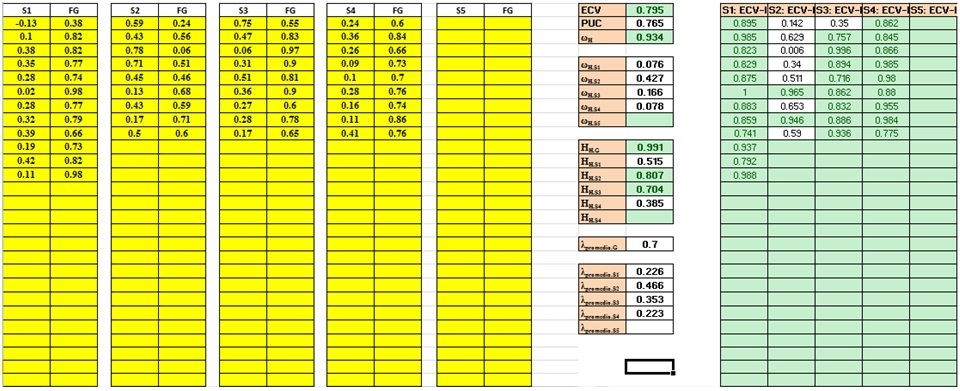
Figura 3. Vista general del módulo IndicesBifactor
Aplicación e interpretación
El uso del módulo IndicesBifactor.xls puede orientarse tanto a la investigación instrumental, como a los re-análisis o análisis complementarios a investigaciones que usaron modelamiento bifactor con el objetivo de extraer información relevante, pero que por diferentes razones no fue reportada.
Por ejemplo, luego de realizar un análisis factorial confirmatorio a un instrumento que evalúa engagement, Stefansson y colaboradores (2016) concluyeron que “…the school engagement is characterized by both a single and multiple dimension (…). Our results suggest that a bifactor model is the best way to represent a comprehensive measure of school engagement…” (p. 479), aunque no se reportaron los índices estadísticos que den soporte empírico a tales afirmaciones. Los indicadores de forma conjunta permiten concluir que el FG es más fuerte que los FEs (Figura 4), de forma similar a los datos presentados por Rodriguez et al. (2016a) (Figura 3).
En ambos casos se aprecia una clara influencia del FG. En el caso de Stefansson et al. el 64% de la varianza en los ítems se debe al FG (ωH = .806). Asimismo, sólo 7% se debe a FE1, 12% a FE2, y un 8% a FE3, explicando de forma conjunta un 27% de la varianza total. También el PUC (.714), ECV (.631) y Hh (.911) evidencian un FG fuerte; pero resulta claro que, a nivel general, el aporte de los FEs a los ítems no es significativo, por lo que la interpretación de los tres FEs de forma independiente sería forzada. Sin embargo, el ωhs del segundo FE presenta una magnitud no despreciable (> .40), e inclusive ECV-I de magnitudes bajas (Figura 4).
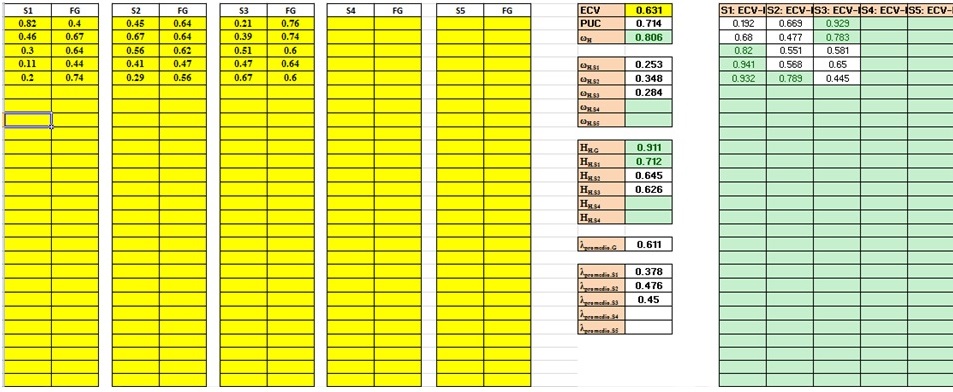
Figura 4. Análisis complementario a Stefansson et al. (2016)
Comentarios finales
El uso cada más vez extendido de instrumentos multidimensionales y la disposición de métodos orientados a evaluar esa multidimensionalidad, obliga al investigador aplicado a brindar todas las evidencias posibles para garantizar un uso apropiado. De este modo, el modelamiento bifactor es una alternativa viable para dicho fin. Adicionalmente, puede ser poco recomendable sustentar todo el peso de la decisión en los índices de ajuste dado que existen otros elementos, como los índices de modificación, que brindaría información adicional y evitarían conclusiones sesgadas (Dominguez-Lara, 2016b). Por tal motivo, es necesario el cálculo y reporte de índices adicionales que permitan ampliar el panorama del investigador, y el módulo presentado (IndicesBifactor.xls), puede ser una alternativa útil en el marco de un modelamiento con estas características.
Si bien en el presente manuscrito el uso del modelamiento bifactor fue ejemplificado en el caso de un FG robusto en el contexto de instrumentos multidimensionales, también puede usarse cuando la correlación entre FEs sea tan elevada, que no sea recomendable una interpretación independiente (p.e., Dominguez-Lara, 2016c).
Por ello, si el investigador decide utilizar un instrumento multidimensional para utilizar posteriormente una puntuación general, es recomendable obtener evidencias empíricas que sustenten su proceder, por lo que el uso de modelos bifactor debe ser más frecuente.
Con todo, es importante mencionar que cualquier procedimiento estadístico debe ser ejecutado a la luz de una teoría que provea significado a los resultados. La razón es sencilla: aunque el FG resulte más robusto que los FEs, si carece de una interpretación teórica coherente por sí mismo, no tiene sentido considerarlo y sería mejor interpretar cada FE por separado (Bonifay, Lane, & Reise, 2017; Dominguez-Lara, & Merino-Soto, 2016; Moscoso, Merino-Soto, Dominguez-Lara, Chau, & Claux, 2016).
CONFLICTO DE INTERESES
Los autores expresan que no hay conflictos de interés al redactar el manuscrito.
REFERENCIAS
Bonifay, W., Lane, S.P., & Reise, S.P. (2017). Three concerns with applying a bifactor model as a structure of psychopathology. Clinical Psychological Science, 5(1), 184 – 186. doi: 10.1177/2167702616657069
Canivez, G. L. (2016). Bifactor modeling in construct validation of multifactored tests: Implications for multidimensionality and test interpretation. In K. Schweizer & C. DiStefano (Eds.), Principles and methods of test construction: Standards and recent advancements (pp. 247–271). Gottingen, Germany: Hogrefe.
Dominguez-Lara, S. (2014). Análisis Psicométrico de la Escala de Bienestar Psicológico para Adultos en estudiantes universitarios de Lima: un enfoque de ecuaciones estructurales. Psychologia: Avances en la disciplina, 8(1), 23-31.
Dominguez-Lara, S. (2016a). Evaluación de la confiabilidad del constructo mediante el Coeficiente H: breve revisión conceptual y aplicaciones. Psychologia: Avances en la disciplina, 10(2), 87 – 94.
Dominguez-Lara, S. (2016b). Evaluación de modelos estructurales, más allá de los índices de ajuste. Enfermería Intensiva, 27, 84-85. doi: 10.1016/j.enfi.2016.03.003
Dominguez-Lara, S. (2016c). Inventario de la Ansiedad ante Exámenes-Estado: análisis preliminar de validez y confiabilidad en estudiantes de psicología. Liberabit, 22(2), 219 – 228.
Dominguez-Lara, S., & Merino-Soto, C. (2016). Análisis Estructural de la Escala de Afrontamiento ante la Ansiedad e Incertidumbre Pre-examen (COPEAU) en universitarios peruanos. Revista Digital de Investigación en Docencia Universitaria, 10(2), 32 – 47. doi: 10.19083/ridu.10.474
Gignac, G.E. (2016). The higher-order model imposes a proportionality constraint: That is why the bifactor model tends to fit better. Intelligence, 55, 57 – 68. doi: 10.1016/j.intell.2016.01.006
Hancock, G. R. (2001). Effect size, power, and sample size determination for structured means modeling and MIMIC approaches to between- groups hypothesis testing of means on a single latent construct. Psychometrika, 66, 373–388. doi: 10.1007/BF02294440
Hancock, G. R., & Mueller, R. O. (2001). Rethinking construct reliability within latent variable systems. In R. Cudeck, S. du Toit, & D. Sörbom (Eds.), Structural equation modeling: Present and future—A Festschrift in honor of Karl Jöreskog (pp. 195–216). Lincolnwood, IL: Scientific Software International
Holzinger, K. J., & Harman, H. H. (1938). Comparison of two factorial analyses. Psychometrika, 3(1), 45-60. doi: 10.1007/BF02287919
Holzinger, K. J., & Swineford, F. (1937). The bi-factor method. Psychometrika, 2(1), 41-54. doi: 10.1007/BF02287965
Morgan, B., de Bruin, G.P., & de Bruin, K. (2014). Operatoinalizing burnout in the Maslach Burnout Inventory – Student Survey: personal efficacy versus personal inefficacy. South African Journal of Psychology, 44(2), 216 – 227. doi: 10.1177/0081246314528834
Morgan, G.B., Hodge, K.J., Wells, K.E., & Watkins, M.W. (2015). Are fit indices biased in favor of bi-factor models in cognitive ability research?: A comparison of fit in correlated factors, higher-order, and bi-factor models via Monte Carlo simulations. Journal of Intelligence, 3, 2 – 20. doi: 10.3390/jintelligence3010002
Moscoso, M., Merino-Soto, C., Dominguez-Lara, S., Chau, C., & Claux, M. (2016). Análisis factorial confirmatorio del Inventario Multicultural de la Expresión de la Ira y Hostilidad. Liberabit, 22(2), 137 – 152.
Raykov, T., & Hancock, G. R. (2005). Examining change in maximal reliability for multiple-component measuring instruments. British Journal of Mathematical and Statistical Psychology, 58(1), 65–82. doi: 10.1348/000711005X38753
Reise, S.P. (2012). The rediscovery of bifactor measurement models. Multivariate Behavioral Research, 47(5), 667-696. doi: 10.1080/00273171.2012.715555
Reise, S.P., Morizot, J., & Hays, R.D. (2007). The role of the bifactor model in resolving dimensionality issues in health outcomes measures. Quality of Life Research, 16(1), 19 – 31. doi: 10.1007/s11136-007-9183-7
Reise, S.P. Scheines, R., Widaman, K.F., & Haviland, M.G. (2013). Multidimensionality and structural coefficient bias in structural equation modeling: A bifactor perspective. Educational and Psychological Measurement, 73(1), 5 – 26. doi: 10.1177/0013164412449831
Rodriguez, A., Reise, S.P., & Haviland, M.G. (2016a). Evaluating bifactor models: calculating and interpreting statistical indices. Psychological Methods, 21(2), 137 – 150. doi: 10.1037/met0000045
Rodriguez, A., Reise, S.P., & Haviland, M.G. (2016b). Applying Bifactor Statistical Indices in the Evaluation of Psychological Measures. Journal of Personality Assessment, 98(3):223-237. doi: 10.1080/00223891.2015.1089249
Stefansson, K.K., Gestsdottir, S., Geldhof, G.J., Skulason, S., & Lerner, R.M. (2016). A Bifactor Model of School Engagement. Assessing General and Specific Aspects of Behavioral, Emotional and Cognitive Engagement among Adolescents. International Journal of Behavioral Development, 40(5), 471 – 480. doi: 10.1177/0165025415604056
Sijtsma, K. (2009). On the use, the misuse, and the very limited usefulness of Cronbach’s alpha. Psychometrika, 74, 107 – 120. doi: 10.1007/s11336-008-9101-0
Smits, I.A.M., Timmerman, M.E., Barelds, D.P.H., & Meijer, R.R. (2015). The Dutch symptom checklist-90-revised: is the use of the subscales justified? European Journal of Psychological Assessment, 31(4), 263-271. doi: 10.1027/1015-5759/a000233
Stucky, B. D. & Edelen, M. O. (2015). Using heierarchical IRT models to create unidimensional measures from multidimensional data. In S. P. Reise & D. A. Revicki (Eds.), Handbook of item response theory modeling: Applications to typical performance assessment, (pp. 183-206). New York: Routledge.
Stucky, B.D., Thissen, D., & Edelen, M.O. (2013). Using logistic approximations of marginal trace lines to develop short assessments. Applied Psychological Measurement, 37(1), 41 – 57. doi: 10.1177/0146621612462759
Ten Berge, J. M., & Sočan, G. (2004). The greatest lower bound to the reliability of a test and the hypothesis of unidimensionality. Psychometrika,69(4), 613-625. doi: 10.1007/BF02289858
Tsubakita, T., & Shimazaki, K. (2016). Constructing the Japanese version of the Maslach Burnout Inventory – Student Survey: confirmatory factor analysis. Japan Journal of Nursing Science, 13, 183 – 188. doi: 10.1111/jjns.12082
Watkins, M. W. (2013). Omega [Computer software]. Phoenix, AZ: Ed & Psych Associates.
Zinbarg, R. E., Yovel, I., Revelle, W., & McDonald, R. P. (2006). Estimating generalizability to a latent variable common to all of a scale’s indicators: A comparison of estimators for ωH. Applied Psychological Measurement, 30(2), 121-144. doi: 10.1177/0146621605278814